���Լ���ܹ������ѧϰģ�͵����Ż��������
|
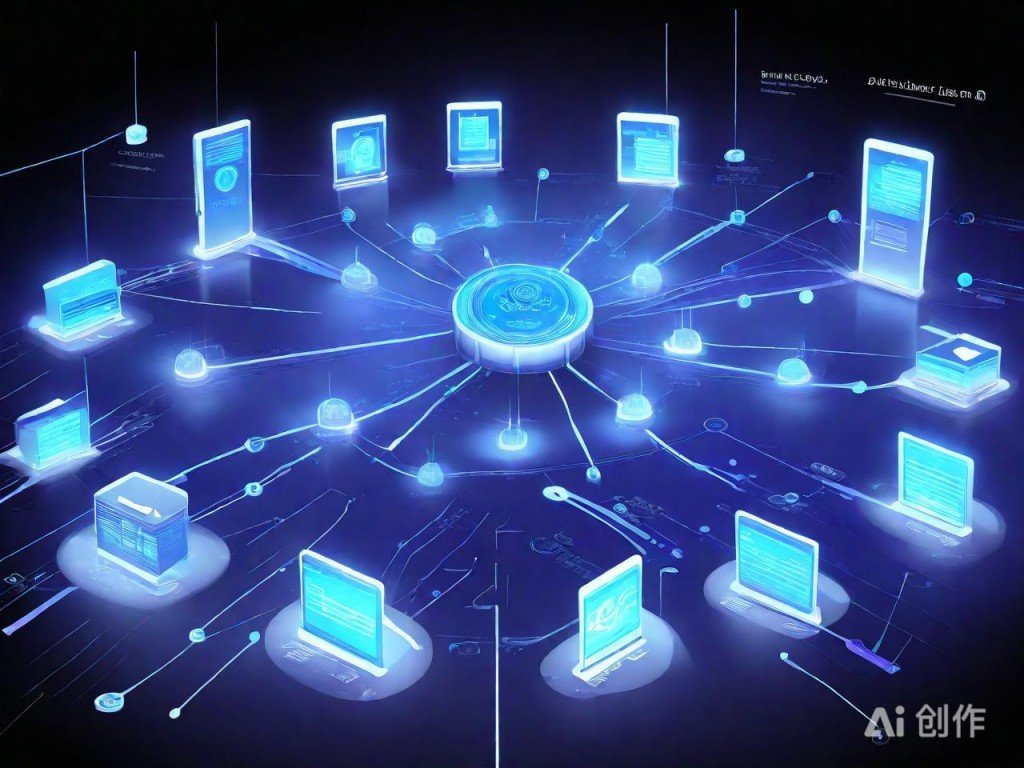
�������Լ���ܹ�Ϊ���ѧϰģ�͵��Ʋ����ṩ�˶�̬������Դ����������ͳ�̶���Դ��������Ӧ��ѵ�����������������������ѵ��ͨ����Ҫ������GPU��Ⱥ������Сʱ�������죬������������Ҫ����ӳ١��߲����������������ҡ����Լܹ�ͨ��������������ڵ㡢�Զ�����ʵ��������������ʹ��Դ�����븺�ر仯ʵʱ���룬�����������óɱ�������������Ӧ���ԡ� ����ģ�������������Ż�����Ĺؼ�ǰ�û��ڡ����ϴ����ƶ�ǰ��Ӧ����������̶ȿ�չ��֦����������FP16��INT8����֪ʶ�����ѹ������������ģ�Ͳ������̼���ʱ�䡢�����Դ�ռ�ã��������˿ɲ����ʵ��ѡ��Χ�������磬���������BERT-baseģ�Ϳ���T4��A10���ж�GPU��ʵ�ֺ��뼶��Ӧ������ǿ�����������A100��Ⱥ���Ӷ��ڵ��Ե����л�ø��������������ȡ�
2026AI���ɵ��Ӿ������������ο� ������������װ������ӿڴ����ǿ����һ���������ֲ�ԡ�����Docker���ģ�͡��������棨��Triton��TensorRT���������⣬��ͨ��Kubernetes����ʵ�ֶั�����𡢽���̽�����Զ�����ת�ơ�������ͻ��ʱ��HPA��Horizontal Pod Autoscaler������CPU��GPU�����ʻ��Զ���ָ�꣨��ÿ��������������Pod���ݣ���������ʱ���Զ����ݣ��������������˹���Ԥ������SLA��ͬʱ������Դ�˷ѡ������ֲ㻺�������Ч�����˼���ѹ�����ڱ�Ե�ڵ��API���ز㲿�������棨��Redis�������ظ�������ݵȲ�ѯֱ�ӷ���Ԥ�������������������̺�ʱ�ij��������ɻ����м�������Ƕ�����������CDN�ַ���̬ģ���ļ�����һ�������������ӳ١��ò��Բ����Ӻ��ļ��㸺�أ�ȴ�ܽ���Ƶ�ͱ䳡���Ķ˵����ӳٽ���30%�C60%���õ�����Դ���۽����������ɻ���Ķ�̬�������� �����ɱ���֪�ĵ��Ȼ��ƽ��Ż�������������ʩ�㡣�����Ƴ���Spotʵ�����зǹؼ�ѵ����������������������ڱ�֤�ݴ�ǰ���½�ʡ�ߴ�70%���ã������߷�������ʹ��On-Demand��Ԥ��ʵ����ͨ��Ԥ���������ݣ��������ʷ����ģʽ�Ķ�ʱ������ƽ�ַ�Ȳ��졣���ƽ̨��ͳһ�ɼ�GPU�Դ桢vCPU������IO�ȶ�άָ�꣬�������Աջ������������緢��ijģ�ͳ����Դ������ʲ���40%��������ʵ��������飬�γɳ����Ż��������� �������Բ������ܽ�ҩ����Ч�ܸ߶�����ģ��������ҵ�����塣ͼ��ָ���ģ�����Դ�������У����ݹ���������OOM������βСģ�������Ȳ�����������ӵ��ȿ�����ʵ����������ʵ����ѹ��Ϊ�����趨������������ֵ����ȴ���ڣ����⡰����ʽ������������Ŀ�겻�����µ��ԣ����ǹ���һ����ԴЧ�ʡ���Ӧ��������ά���Ӷ�����ƽ��Ŀɳ�������ʽ�� ���༭���ٿ�վ������ ����������վ���ݾ��������磬��������۽��������߸��˹۵㣬��������վ�������������ַ�������Ȩ�����뼰ʱ����ϵվ��ɾ���������! |